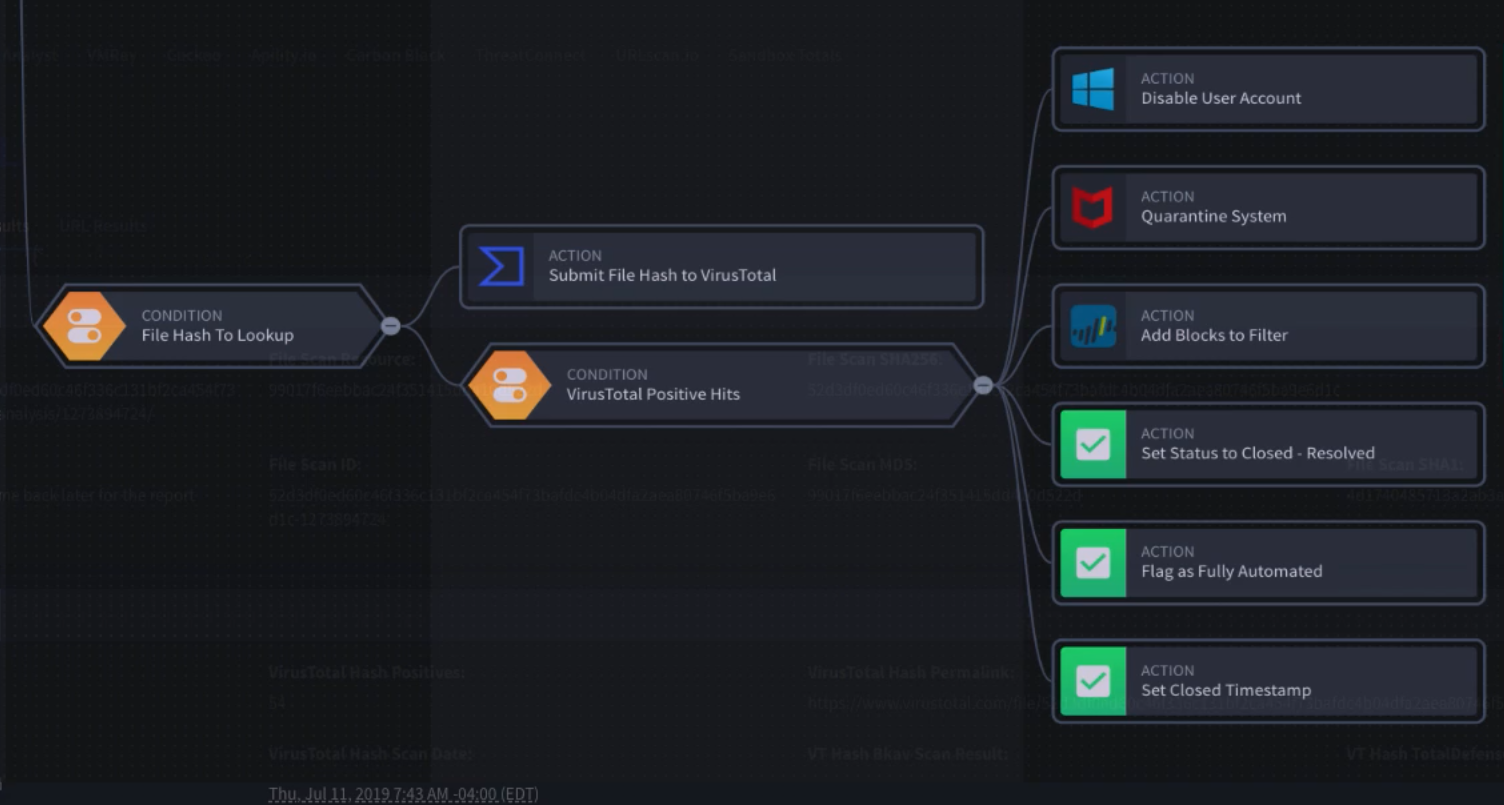
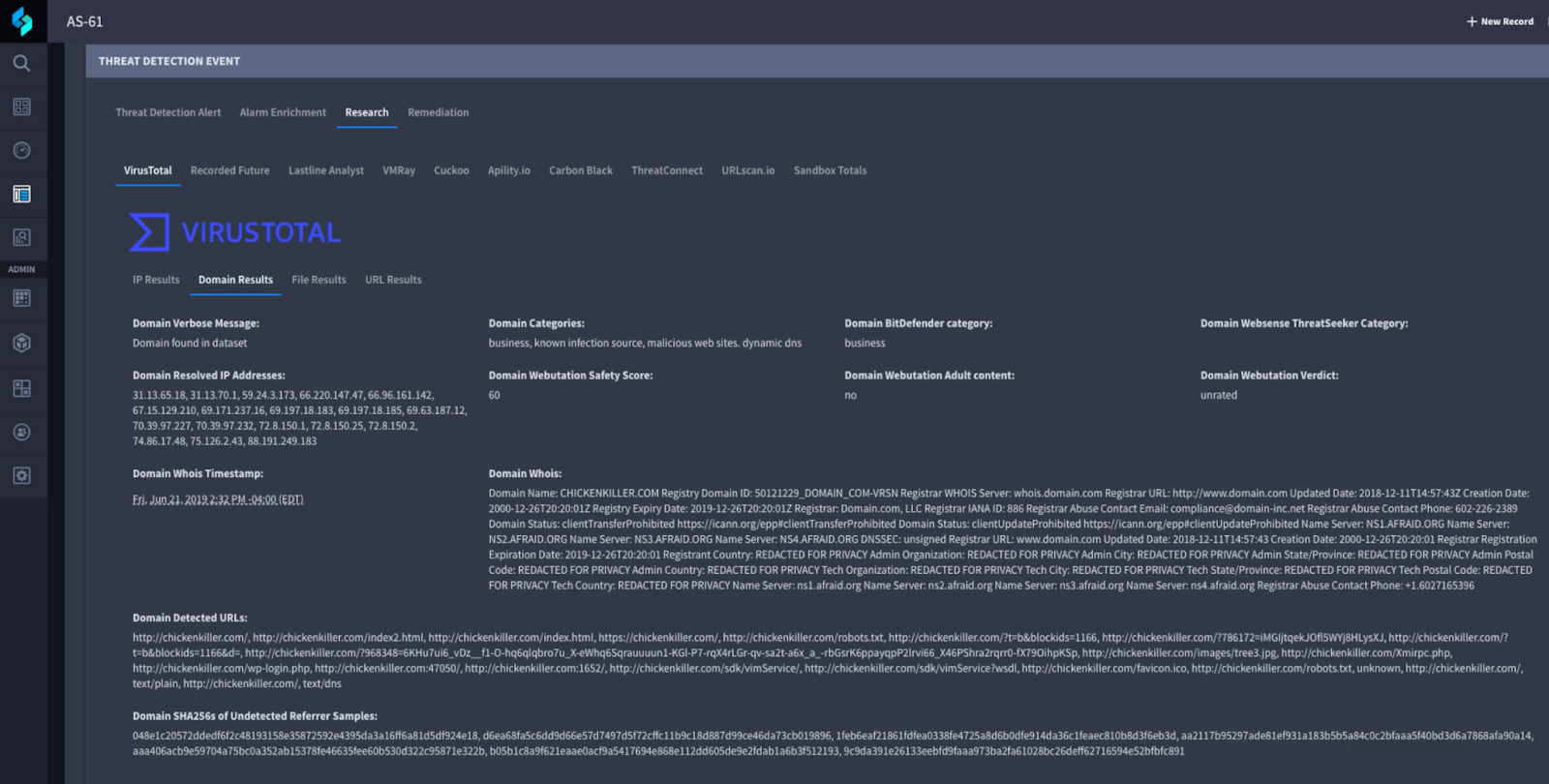
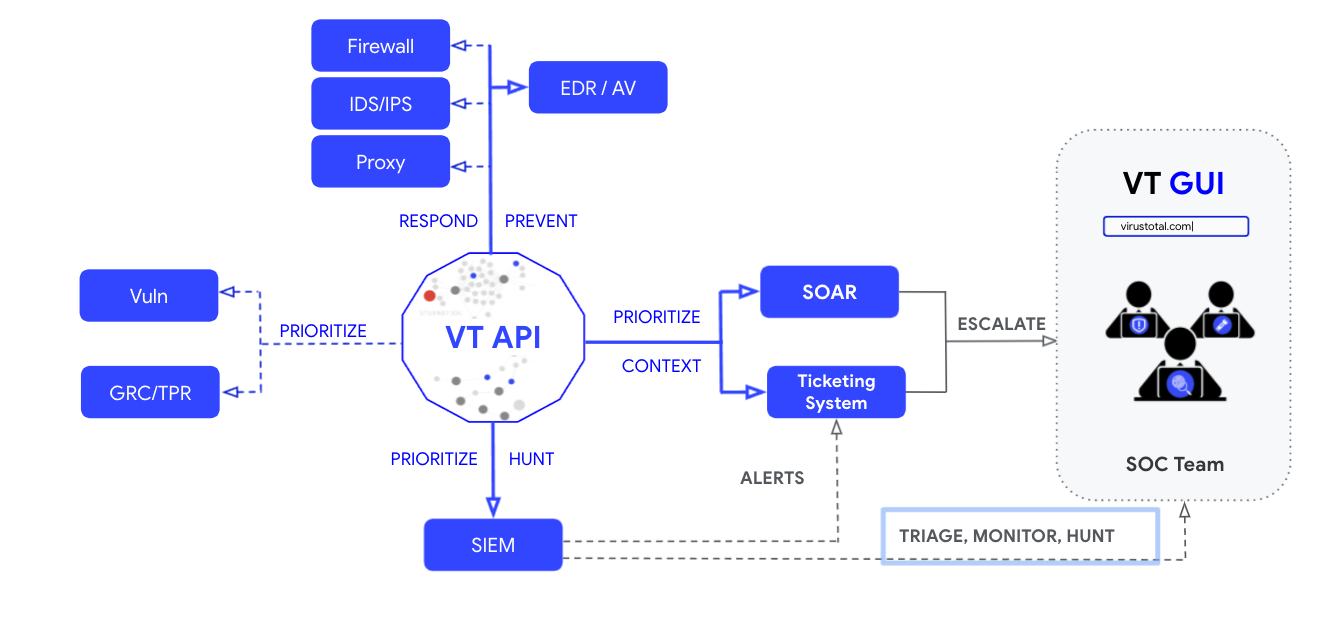
We wanted to reflect on this and other recurrent questions we received since the publication of our report with our colleague Vlad Stolyarov from Google’s Threat Analysis Group (TAG) to help provide some further insights into them.You can also find some of the answers and great additional content in our beloved Cloud Security Podcast by Anton Chuvakin and Tim Peacock Episode 45 “VirusTotal Insights on Ransomware Business and Technology”.
Alright, let’s go check some of the most popular questions we received.
Can you provide more details on the geographical distribution of the samples? How is it possible the US is not the main target?
Well, North America remains the most targeted region by number of ransomware samples according to our visibility.
What we show in the report is the difference between the normal average submission of samples from any given territory and ransomware submissions. We did our best to filter out automatic submissions or any other systems that could alter the real spreading, but obviously there can be exceptions. In the case of Israel, we believe the dramatic increase is a combination of being highly targeted by ransomware and several security companies or experts submitting to VirusTotal.
Why was GandCrab the most popular family in 2020? Does it continue to be the biggest one by number of samples?
GandCrab was one of the most successful groups implementing the Ransomware-as-a-Service (RaaS) distribution model. Indeed, anyone could sign up on their portal to be an ”affiliate”, getting a significant commission from each ransom payment made by victims. This made this actor very successful, which created a snowball effect where ransomware affiliates preferred GandCrab over other RaaS programs as branding matters in the ransomware business. Despite the fact that several versions of GandCrab had cryptographic flaws, with free decryptors available on the NoMoreRansom project website, it remained popular. That didn’t stop this actor making (as they claimed on forums) more than 150$M in a year.
Now, GandCrab RaaS program is believed not to be active since mid-2019, and yet VirusTotal still sees a large number of samples detected as GandCrab, even in 2021. Why? Our hypothesis is as follows:
1) Many TTPs (Tactics, Techniques and Procedures), initially popularized by GandCrab were later weaponized by other, unrelated commodity ransomware families. Antivirus engines, however, largely continue to associate and detect samples utilizing these TTPs as GandCrab.
2) While it was still active, GandCrab employed a number of distribution mechanisms. In addition to the more traditional vectors such as malspam, it used trojanized software, torrent sites, and a wormable network exploit EternalBlue to infect machines in the organization’s network.
Actors behind GandCrab have since moved on and are now believed to be related to the infamous REvil/Sodinokibi Ransomware-as-a-Service, which shares big portions of code and other indicators such as PDB strings with GandCrab. “Rebranding” of GandCrab as REvil/Sodinokibi follows a general trend in ransomware where many actors have switched from targeting individuals to larger corporate organizations in the past two years.
REvil, following GandCrab’s footsteps became very popular and is infamously known for several high-profile attacks: triple extortion attack on Quanta Computer who is an Apple supplier, threatening to release confidential information on unpublished products; JBS, a large meat processing company; Kaseya supply chain attack affecting multiple managed service providers and their customers.
On latest news, some REvil affiliates were recently arrested by law enforcement, following a coordinated takedown operation with an infrastructure takeover. Around the same time BitDefender published a free universal decryptor. As a result, REvil Ransomware-as-a-Service announced it’s shutdown and we have yet to see if they will resurface under a different name, once again.
What are double extortion schemes?
Ransomware actors use double or even triple extortion schemes as an additional method to force victims to pay ransom. In a double extortion scheme, in addition to encrypting victim’s data, attackers also exfiltrate critical data and threaten to publish it unless the victim pays. Under triple extortion schemes, ransom demands may also be directed at a victim's clients or suppliers. At the same time, further pressure points such as Denial-Of-Service attacks, or direct leaks to the media, are also brought into the mix.
Is there any ransomware malware on macOS?
Ransomware on macOS is possible, but much less frequent than in other platforms. One example would be the (opportunistic) EvilQuest/ThiefQuest family discovered in mid-2020, which had ransomware functionality, although it’s not clear if that was the main goal. ThiefQuest is also a very representative example of ransomware on macOS - despite only demanding 50$ payment in Bitcoin, the wallet specified in the ransom note had received exactly zero transactions, meaning no user had decided to pay to get their files decrypted (well, that, and the fact that free decryptor is also available).
There are several potential explanations to this:
targeting corporate victims is far more profitable than targeting individuals, and most organizations are still using Windows-based environments.
low level of expertise and experience in writing macOS malware amongst ransomware developers.
It exists! BlackMatter and REvil both have versions for Linux. As more organizations are investing in virtual machines and file backup servers, ransomware groups are increasingly developing Linux variants, targeting specifically VMWare ESXi and NAS servers - this increases the likelihood of victim organizations paying the ransom as they have no way of restoring data or their infrastructure.
Do we expect exploits and 0days to become more popular in ransomware attacks?
Yes, but with a catch. Traditionally, office exploits (not necessarily 0days) were always popular amongst financially motivated actors and this is not unique to ransomware. In addition to that, profit from a successful ransomware attack is often enough to buy a 0day or two, but what’s the point of burning expensive 0days on individual users (even if they are employees of a large organization), when phishing is just as effective? On the other hand, we’re seeing an increasing amount of interest in remote vulnerabilities targeting server software - anything from VPN to mail servers and domain controllers. But to each rule there are exceptions: a recent example would be a remote code execution vulnerability in MSHTML, CVE-2021-40444, which was used as a 0day from a Word document in a Big-Game-Hunting (BGH) campaign in September to deploy ransomware.
You can use VirusTotal Intelligence to monitor samples related to CVE-2021-40444 using the following query: “tag:cve-2021-40444”.
Any info/insight on how ransomware operates internally" and why it works so well [for them]?
Ransomware groups are organized criminal activity with people working weekdays, 9 to 5. “Employees” have clear roles and responsibilities such as IT support, system administrators or developers. As crazy as it sounds, some employees might be unaware of who they’re working for. This description fits well for the biggest actors who previously used to be in Point-of-Sale/Banking/Carding areas, like FIN7, who are also attributed as operators of the DarkSide/BlackMatter RaaS.
As a final note, we recommend checking our original post to find more details on how to monitor ransomware activity before being hit. We will continue sharing relevant malware related information to keep our world a little bit safer. As always, we are happy to hear from you.
Happy hunting!