

The concept of similarity is pretty straightforward: are two files similar? There are many ways to figure it out. That's why different similarity algorithms exist. Now, why is this useful?
Attackers need tools for their attacks, basically malware. Malware in the end is a piece of software, built from frameworks, code and libraries, and takes some time and expertise to create. The result is that two different malware files built from the same developer using the same pieces will look alike.
Imagine you are investigating some attack and you find some suspicious file. After taking a look in VirusTotal, you find nothing really meaningful about the file itself. One idea at this point would be finding similar files: maybe the attacker used similar malware in other campaigns than the one under investigation, and maybe these files will tell more about the infection chain and infrastructure. Here is where similarity comes handy!
Additionally, the same approach can be applied to attribution. We find some malware that looks new, there are no references about it. Can we find similar malware? Maybe the new artefacts will tell more about the author, maybe they are well-known by the security industry. This is how attribution is built in many cases.
There are many situations where similarity becomes useful. We can always reduce the problem to the following: IOCs can easily be replaced, malware frameworks not.
If you want to know more about how to use similarity in real cases, join us next November 25th for our “Similarity brings your threat hunting to the next level” webinar with TrendMicro and Trinity Cyber. Register here.In this blogpost we will discuss some interesting ideas of what can be done with similarity in VirusTotal.
File similarity in VT
You came across the following sample c9b96d5d694e4e25e03d97c7b95eff637525e539b9c47c8eda498f72ecd51b22 within your network and you want to find some context. Crowdsourced sigma rules already warn that something fishy might be going on.

At this point we want to get a better understanding of the whole picture, which means getting more artifacts. When we run out of indicators, similarity to the rescue!
How to find similar samples? Right from the Details panel in the sample report there are several hashes that correspond to the output of different similarity algorithms: vhash, authentihash, imphash, rich PE header hash, ssdeep and TLSH:
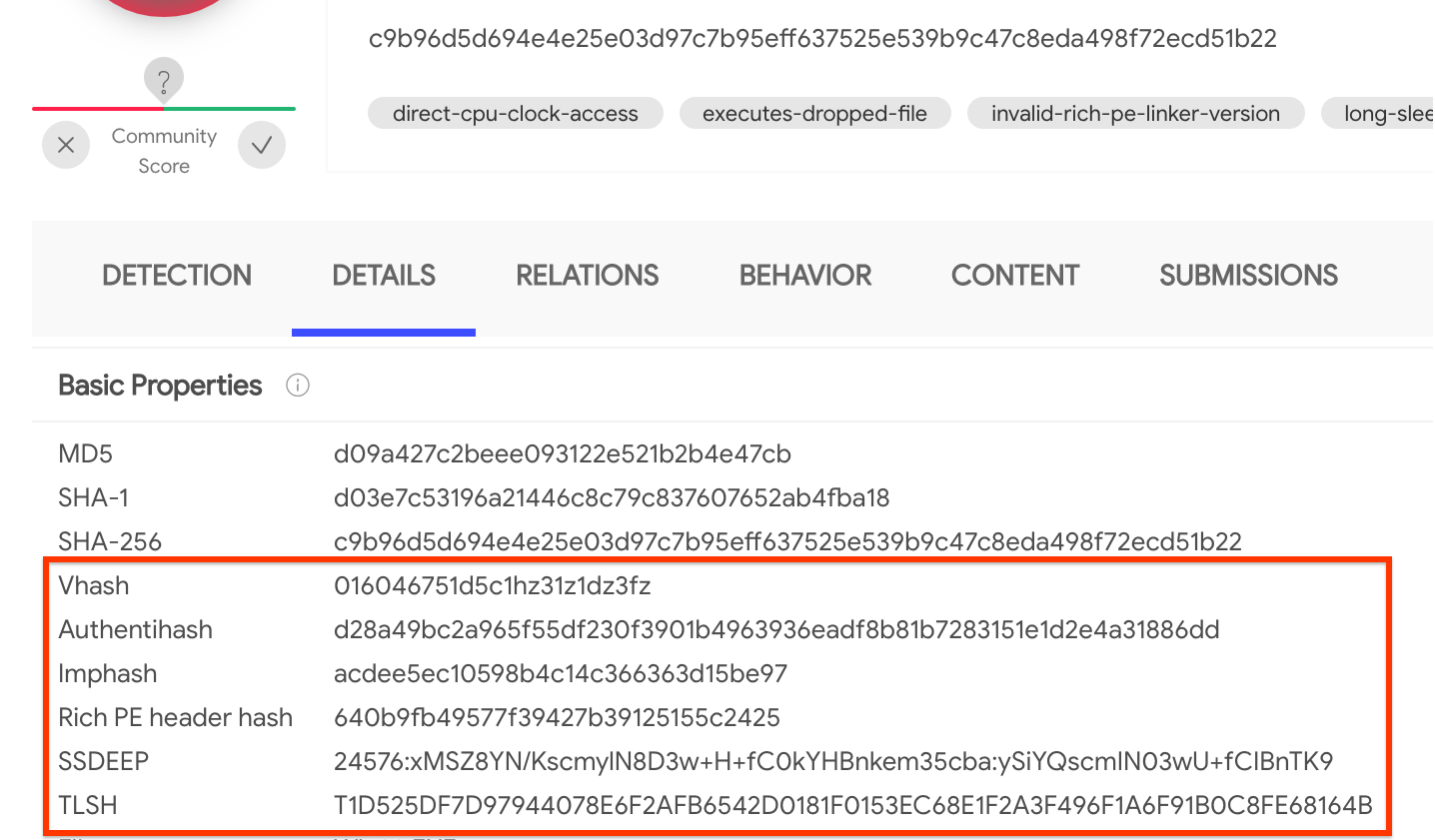
It is important to understand that different similarity algorithms provide different results. Choosing the right similarity many times depends on the samples we are working with, that's why sometimes it is just easier to check them all at the same time and take a look at the results.
Clicking on any of the hashes shown in the report will return all similar samples. In this case, vhash returns 57 additional files, imphash finds no other hits and rich PE header hash returns around 1.16 million other files in VT (we can spot potential non-malicious files adding the search operator positives:0).

All the above might sound too technical, that's why sometimes we can approach this similarity problem with a different angle. For instance, we implement visual similarity. This is specially useful for suspicious documents distributed by attackers, but it also works for executables sharing similar icons. In this case, visual similarity returns 3,390 new files by clicking on the icon above.
We do our best to detonate in a sandbox every file we receive in VirusTotal. Would it be possible to find files with a similar behavior? It is! Even better, we integrate multiple sandboxes, offering us different options. We can do this similarity search either by selecting it in the multiple similarity button, or in the Behavior tab. Following the example, JujuBox behaviour similarity returns 11 additional files. This is an interesting feature when we want to make TTPs actionable, but we will get back to all these topics in a future post.
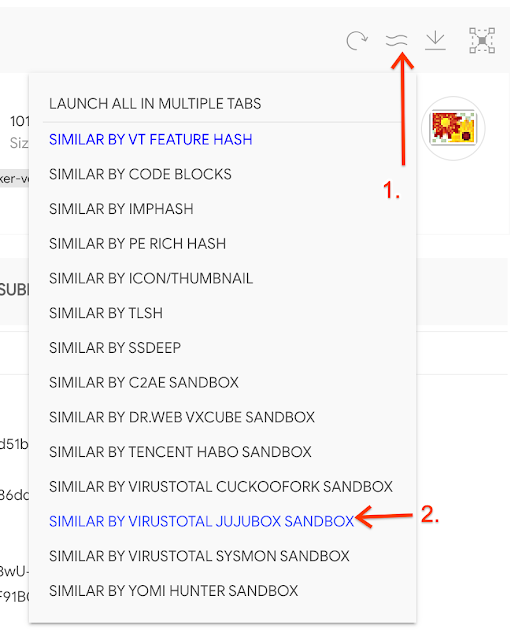
We have used clustering hashes (both static/structural and behavioural), but are there concrete features that we could pivot on? We can look at the Capabilities and Indicators. Specifically, let's try to find some pivotable features (or clues) among the million files caught by rich PE header hash using the VT Enterprise query [rich_pe_header_hash:640b9fb49577f39427b39125155c2425 have:clue_rule]. One of the results, 15e5353c8d5d1b1dba8d9c99e77075d737771335eac9597eba95d1f3efc3b6cd, shows interesting dropped files, registry keys set and DNS resolutions in the Details panel. We can click in any of these indicators to find their respective clusters.

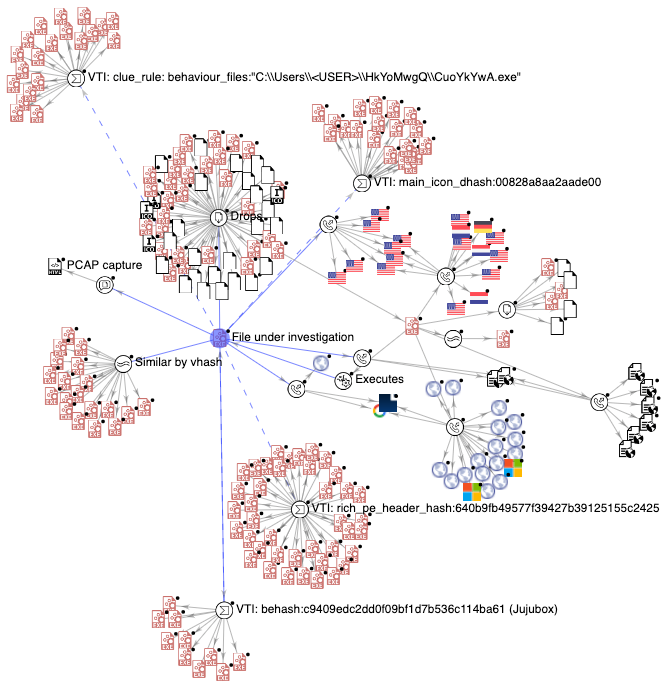
To sum up, once we understand the value of using similarity for our threat hunting, it is very important to have all the options available depending on our needs. Different investigations, or different malware families, need different approaches. Behavioural similarity for instance can be very interesting when the samples are different but the TTPs are common.
But we cannot apply similarity without any data to compare. In VirusTotal we have 2.5 Billion files to make sure you get the most from your Threat Intel investigations.
Happy hunting!
0 comments:
Post a Comment