

by Vicente Diaz (@trompi) from Virustotal, Costin Raiu (@craiu) from Kaspersky and with the kind support of Victor M. Alvarez (@plusvic) from Virustotal
Introduction
On August 31, 2021 we ran a joint webinar between Virustotal and Kaspersky, with a focus on Yara rules best practices and real world examples. If you didn’t have the chance to watch the webinar live, you can see it as a recording on Brighttalk: Applied Yara training.
During the webinar we received an overwhelming response and we would like to thank all the participants for sharing their thoughts, questions and ideas; most of all, we are happy to see so much interest and enthusiasm for Yara!
During the 90 minutes of the webinar we only had the chance to answer a fraction of the questions we received. We would still like to answer the remaining ones, since we thought a lot of them are quite relevant to real world situations, practices and could be useful to other security practitioners. Even better, for the more tricky questions we decided to ask for help from the creator of YARA itself, Victor Manuel Alvarez (aka Hector Manuel Velasquez) who will help answer them. If you have further questions, please feel free to send them to us in the comments section. We will be happy to answer them too!
Stay safe, stay secure and Happy hunting!
Costin, Vicente and Victor
RULE WRITING
Q: How difficult is it writing a YARA rule for obfuscated payloads? What file features normally you experts often look into when it comes to obfuscated files? How can YARA help? What would be your tip / best practices for writing rules to catch obfuscated binaries?
Vicente here. Obfuscated files are tricky, but YARA can still be useful. We can use all the metadata and file geometry for the detection. Also, depending where the obfuscation is, maybe we can also use some portions of the code for the detection - for instance if it only obfuscates strings with some custom method, maybe the code used for obfuscation can be useful.
Costin here. In general, it is a lot more difficult to write Yara rules for obfuscated payloads. Depending on the obfuscation method, one can still find some ways to detect them. For example, assuming a specific cryptor or packer was used, you can still write a rule for the packer (eg. UPX) or, rely on an unpacking engine to give you the plain code. Some platforms, such as VirusTotal, would automatically unpack known tools for you, which allows one to write simple Yara rules for the unpacked code. When the obfuscation is polymorphic, for instance, the code is expanded with dummy instructions and operands are split within several operations, once can try to use other file properties, such as metadata, entropy, import hashes or other data which stays constants across different generation. In short, there is no rule on how to write rules for obfuscated code, but in some cases, it is possible.
Q: Do hashes used for API hashing for example would be helpful for a YARA rule? Since this can change in a future campaign, i'm in doubt
Costin here. Absolutely - API hashing can be super useful for detection of malware, especially when there are very few unique strings that can be used in the rule, or, when the malware is otherwise obfuscated. Yara actually provides a nice easy to use solution - the pe module implements the standard Mandiant import hash function as pe.imphash(). This can be used in a Yara rule condition such as:

Q: Are you trying rules against a set of malware before releasing it ?
Costin here. Yes, extensive QA of a Yara rule is critical for us before releasing it publicly or to customers. For this purpose, we use several internal databases, of both malicious files and known clean code. To make sure the Yara rule detects more than just one sample, we try to run it against our entire malware collection, which is over 5 petabytes at the moment. Sometimes, when time is essential, we run it on a subset of the malware collection, such as specific PE files received during the last 12 months, or, say, script files. In many cases, testing a rule on clean files is even more important than testing it on malware! Based on our experience, we’ve seen countless instances of Yara rules that were published by security companies or even governmental agencies which produced false positives when used on a real system. To simplify testing of Yara rules, you can either use VirusTotal’s Retrohunt feature, or set up a test of your own collections using our open source KLARA project.
Q: Won't typos also restrict the Yara rule to a particular sample or samples distributed under one campaign?
Vicente here. That could happen, but maybe the typos are difficult to replace. For example, sometimes typos are in the commands that the malware receives from the server, which would need a redeployment of server and client side malware from the attacker. In some other cases attackers get fully unaware of the typo, maybe because they are not familiar with the language and just use a weird expression that no native speaker would use, and can stay there forever. We can find these typos everywhere, including metadata, comments, etc.
Q: Where are good sources for large amounts of known good clean data?
Costin here. There are several public, free good sources of known good clean data. Some have suggested the NIST reference set, however, you can also build your own from things like a Windows installation, Linux install, Android/iOS dumps and the likes. It’s important to also have third party software, such as Chrome, Firefox or Adobe Reader. A lot of false positives produced by publicly available Yara rules occur on software such as the ones above!
Q: How useful are Yara Rule Generators like Florian Roth's yarGen?
Vicente here. Yara rule generators are VERY useful, but we do not recommend using raw generated rules without an extra round of manual polishing. We believe it is more useful to use it for a first round to extract potentially relevant strings from a collection of samples we are analyzing, and from here use these results to help us build more refined rules.
Q: Is it better to use wide, wide ascii, both, or none?
Costin here. Using wide, ascii or both (or none) depends on a case by case basis. Depending on how a malware piece is compiled, the strings you see inside could be ascii (single byte) or wide (double byte, Unicode). Yara allows you to easily search for UTF-16 strings through the wide modifier. By default, ascii is used every time you assign a string to a variable, however, if you want to search both, you need to use “ascii wide”. Adding “wide” to the ascii strings you are searching for might find you additional stuff.
Q: If a rule generates false positives on a very specific sample, would you suppress a specific hash in the rule directly or rather improve the whole logic?
Vicente here. The answer is - “it depends”. If there is a very particular binary that produces a false positive in an otherwise solid rule, we can keep the rule as long as we know what we are doing - for example we use it for hunting privately, and just exclude that specific FP file by hash. In case this rule would be used externally or automatically, for instance in a production environment for detection, then better to avoid this false positive in the logic.
Q: some programming languages have automatic formatters (like 'black' in Python, or gofmt in Golang) -- do you recommend something similar for Yara, to maintain good formatting across a team?
Víctor here. As far as I know such a tool doesn’t exist. There are some alternative parsers for YARA, which are able to read a YARA source file, build an abstract syntax tree (AST) from it, and regenerate the source code from the AST. But they have limitations that make them unsuitable for building a tool like gofmt (for example the comments are completely lost).
YARA INTERNALS
Q: Does yara "digest" and optimize a ruleset for example user writes "i001" and "i001"
Víctor here. YARA doesn’t perform any optimization on the condition, they are evaluated exactly as they are written. No attempt is made to detect useless branches in the condition, if you write “X or Y or Z or true” YARA evaluates X, Y and Z, it is not smart enough to realize that the condition is always true. Also, if you use the same pattern/string in different rules they are treated as if they were different, YARA doesn’t realize that you are searching for the same string.
Q: Can YARA run on only files with Mac OS xattributes for example com.apple.metadata:kMDItemDownloadedDate, com.apple.quarantine?
Vicente here. At the moment, I’m not aware of any module able to interact with them.
Q: I have seen that hash is case sensitive .. i have to use lower case . Will this change in future?
Víctor here. The next version of YARA will include the icompare operator for case-insensitive string comparison. The == operator maintains its case-sensitive semantic when used for comparing strings, but with icompare you don’t need to worry about whether the values returned by the hash module are upper or lower case.
Q: Does YARA see filename in the file set?
Vicente here. At the moment, you cannot specify any condition about the filename in a rule, as YARA is designed just to check the content and structure of the file and the file name can easily change. Nevertheless, this option exists in case you use the VT YARA module, which is available to take advantage of file metadata for YARA rules running on VirusTotal. You can also use the -D option to define a variable in the rule that contains the filename.
Victor here. I would like to provide more context about this. The reason for not including a “filename” keyword in a similar way to “filesize” is because “filesize” makes sense in almost any context (except when scanning a process address space) as the data being scanned always have a size. However, “filename” makes sense when you are using the yara command-line tool for scanning your hard drive, but it doesn’t make sense where YARA is scanning the data without knowing where the data comes from. However, due to the high number of times I’ve seen this question asked, I’m considering some intermediate solution, like allowing the command line tool to define a variable that automatically takes the name of the current file.
Q: Is it possible to use YARA to monitor strings in PDF documents? Or is it medium-dependent?
Vicente here. It is possible. However keep in mind that strings are not represented inside the file the same way they are displayed to a reader. It is important to check the content of the file itself with utilities such as “strings” or with any hex editor, and select which strings can be used for a YARA rule. But it will not necessarily work if you select strings based on how they appear in the PDF when displayed.
Q: Is YARA compatible with the ELK stack?
Vicente here. There are different available options, like plugins to incorporate events matching YARA rules into Elastic, for example.
EFFICIENCY
Q: Is uint16(0) faster than $magic at 0? (Where $magic is the hex value)
Vicente and Costin here. The $magic check should be considered obsolete and is hopefully not used anymore in any public rules. Please kindly use uint16(0) or the Magic module instead. This is because defining a string such as $mz=”MZ” will cause Yara to search for this short string and save all the matches in a file, no matter the offset, which greatly increases the resource overload. This slows down scanning and eats up more memory. In general, short strings should be avoided in Yara rules for this reason, or always followed by the “fullword” modifier.
Q: In your experience, is CPU or I/O the bigger constraints? Can YARA run at low-priority? only on user idle restricted to time schedule? I am thinking about tunability like worldCommunity grid. Does YARA use sophisticated I/O scheduling?
Víctor here. That depends a lot on your rules. If you have a few high-performance rules the bottleneck will certainly be I/O, but it can change drastically if you have many rules or they are not very fast. YARA doesn’t do anything special with regards to I/O, it just uses memory-mapped files and relies on the operating system for I/O. Both in Windows and Linux, YARA tells the operating system that files are likely to be read sequentially, so that the OS can take that into account and read-ahead aggressively.
Q: Hello. Is the “nocase” option efficient? We can never know what case we can find in a malware file, and maybe the “nocase” option increases the search time and the used resources. How to determine if we need this option?
Víctor here. It depends on the string, but generally speaking “nocase” introduces a performance penalty and it should be avoided if possible. Many people use “nocase” and “wide” just in case. They are not really sure about it, but they use them because it doesn’t do any harm (or so they think). My advice is doing exactly the opposite, if you don’t have a clear reason for using those modifiers, don’t do it. If you know for sure, or have good reasons for believing that the string can appear in some arbitrary casing, use “nocase”, but avoid it if otherwise.
Q: My understanding is that the 'filesize' condition is evaluated AFTER all strings have been processed. If this is the case, then filesize cannot be used to make rules more efficient by eliminating samples based on filesize BEFORE strings are evaluated. Is my understanding correct? If so, do you know the reason why filesize is evaluated after strings?
Víctor here. That’s 100% correct. The reason for that behavior is that YARA is optimized for the case in which you have many rules. From the performance standpoint the best thing to do when you have a lot of rules is scanning the file in a single pass first, looking for all the strings from all the rules at once, and then evaluate all the conditions. Evaluating the conditions first, searching for each string individually as they are used in the condition does not scale well when you have thousands of rules. With a very high number of rules the odds are that you are going to need reading and scanning the file anyways, as at least one of your conditions won’t filter out the file because of its size.
USING YARA
Q: if you have a mature team, and a large set of rules that were developed over time --- do you have any thoughts on how to go back and re-evaluate if rules are still good, or need to be updated? (and how often, etc.) -- or other ways to track metrics on each rule. ('hey, this one fired once, and it was a great find -- this 2nd one fires with every SCR, and needs some work')
Vicente here. This is an excellent question. What would be important is to create a policy based on your needs and how you use these rules. Some of the rules can be valid for years while others can change very rapidly, and that depends both on the rule itself and on the threat they monitor. It is always good to have a baseline detection per rule (what it should be detecting) and find alternative methods to double-check these detected samples indeed belong to the family/actor you are monitoring. From this point, you need to work on keeping updating these rules, detection methods and detected samples triad regularly, polishing rules as needed and replacing them once they are not relevant anymore.
Q: Is there a way to centrally run YARA rules to all network workstations without depending upon other third party tools like Nessus or supported antivirus platforms?
Vicente here. There are different EDRs and utilities to do so. However this kind of practice tends to be overkill in most cases. We recommend carefully selecting what rules to run, what folders and adding further conditions to the rules in order to avoid scanning unnecessary files (you can play with conditions such as file format, size, timestamps, etc).
Q: We have tried YARA ourselves and there's no doubt about the capabilities. What we want to understand is what is the correct way to leverage Yara? Shall we scan some workstations regularly with industry/region specific threat intelligence? Or a better approach could be to run periodic scans based on targeted hypothesis based threat hunting? Shall we only run it to investigate incidents?
Vicente here. This totally depends on your goals, as all the above are very usual use cases. In most of the cases, you want to regularly scan a small percentage of sensitive or suspicious files on a regular basis. The same with your rules, you want to maybe use the ones corresponding with active and relevant threats. In parallel, you will always have your collection active for hunting and ready for any IR/forensic if needed.
Q: Can we also search within memory with YARA?
Vicente here. It is possible. There are several EDRs and tools that allow you to do so. Also, it is always possible to use YARA against a memdump, for instance using Volatility. Last but not least, you can directly scan a running process, if you know it’s PID, by running “yara rule.yara PID”.
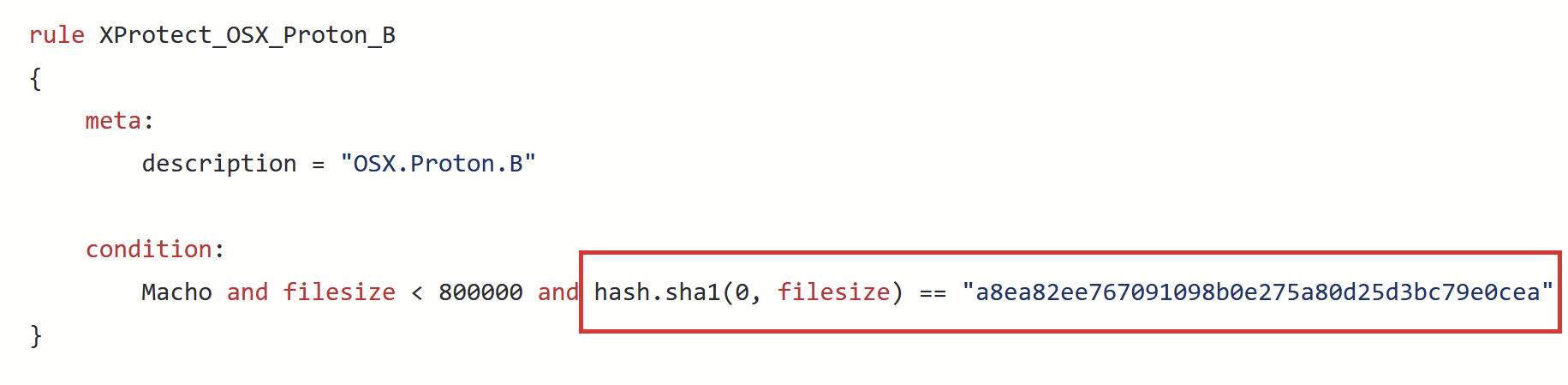
Q: Is it possible to utilize hash detection with YARA?
Vicente and Costin here. Yes, it is. You can use the “hash” external module and calculate different hashes for files or sections. Here’s an example of such a rule from Github Xprotect.yara:
Q: What do you recommend for managing a large collection of YARA rules? (Deduping, updating versions, etc)
Vicente here. We do not recommend any utility in particular for this, many researchers simply use GitHub. Our recommendation in terms of procedures would be always checking that rules detect what they are supposed to detect and checking against false positives, and to do this regularly. One utility you can use in this direction is YARA-CI. We also recommend having different collections for different purposes, for instance Incident Response, Forensic, Hunting, Mem-scanning, etc.
Q: How can we start using YARA for malicious email attachments
Vicente here. There are different mail security appliances that allow you to do so. You can always check attachments separately.
Q: For memory dump, I was not able to scan directly by attaching it, rather I had to mount its file system (E.g. MemProcFS) before Yara can work. Am I correct?
Vicente here. Right. Another option is using the dedicated utility in Volatility to run YARA against memdumps.
VIRUSTOTAL
Q: Will VT allow us to scan older parts of the corpus with retrohunt?
Vicente here. At the moment, VirusTotal Retrohunt works on a 90 day back index that can be expanded to 1 year depending on your subscription.
Q: Yara rules can be shared with the VT community? or these only can be shared from user to user
Vicente here. We incorporate a number of repositories from the community as crowdsourced YARA rules, you can find a list of contributors here. If you would like to contribute, please contact us!
Q: Can we find strings inside pdf files on virusTotal with YARA rules? we can see it working on other files types but not on pdf, we didn't really see it working and could not find something about it on the VT YARA documentation.
Vicente here. As described in a previous question, nothing changes when using VirusTotal to find a string within a PDF than when using YARA in any other environment.
Q: What are ways of hunting with YARA beyond virustotal?
Vicente here. Hunting is a technique/art/discipline that can be done on any platform. Basically you just need a collection of data you can explore to find what you are looking for. Usually that would mean a collection of malware with as much data on top of it as possible. In VirusTotal we work hard to make it as convenient as possible.
MISC
Q: Also consider that you can tip off the threat actor that you have found their malware…
Vicente here. This is true. Many actors are interested in understanding how they are detected, which can become quite obvious when checking YARA rules publicly available. It is a cat and mouse game, but happily the fact that actors understand how they are being detected doesn’t mean they can avoid it in an easy or quick way.
Q: Can anyone explain why YARA was created with a unique schema (yet similar) compared to SQL? Do developers see YARA rules as a catch-all rule writing standard that will eventually become a standard for querying any data? I find YARA rules far easier to write/read than many formats, and it seems more modern, but the evolution is unclear.
Víctor here. The syntax was created with legibility in mind because YARA rules are intended to be created/consumed by humans. The idea was creating a language that looked more like a programming language than like SQL, in fact you can find reminiscences of C in YARA’s syntax. However, YARA doesn’t pretend to be a general purpose query language for usages outside the scope it was designed for. Any future enhancements in the syntax will be oriented towards improving expressiveness and legibility, but always within the boundaries of its current purpose.
Q: How do you communicate the importance and utility of incorporating threat hunting techniques (like writing Yara rules) to muggles?
Vicente here. Threat Hunting is one of the best techniques we have. We use it to defend ourselves from current attacks, by expanding our visibility and establishing monitoring on threats targeting us. It is also one of the most powerful weapons we have to detect unknown threat activity.
Q: Maybe I'm jumping ahead, please forgive me if I do; but how do commercial Anti-Virus companies use YARA to determine whether a file is being malicious? How do you deal with false-positives?
Vicente here. YARA is one of the methods or engines that AV companies might use to determine whether something is malicious. In essence it is not different from other methods, and depending how it is being used can lead to False Positives. As it usually happens, this has nothing to do with the tools used but with how solid the rules are, if they are being double-checked with any second method, if there is a reputation system in place, how good the heuristics are, etc.
That’s all for now!
Stay safe everyone and hope to see you at our next webinars!
Online resources:
0 comments:
Post a Comment